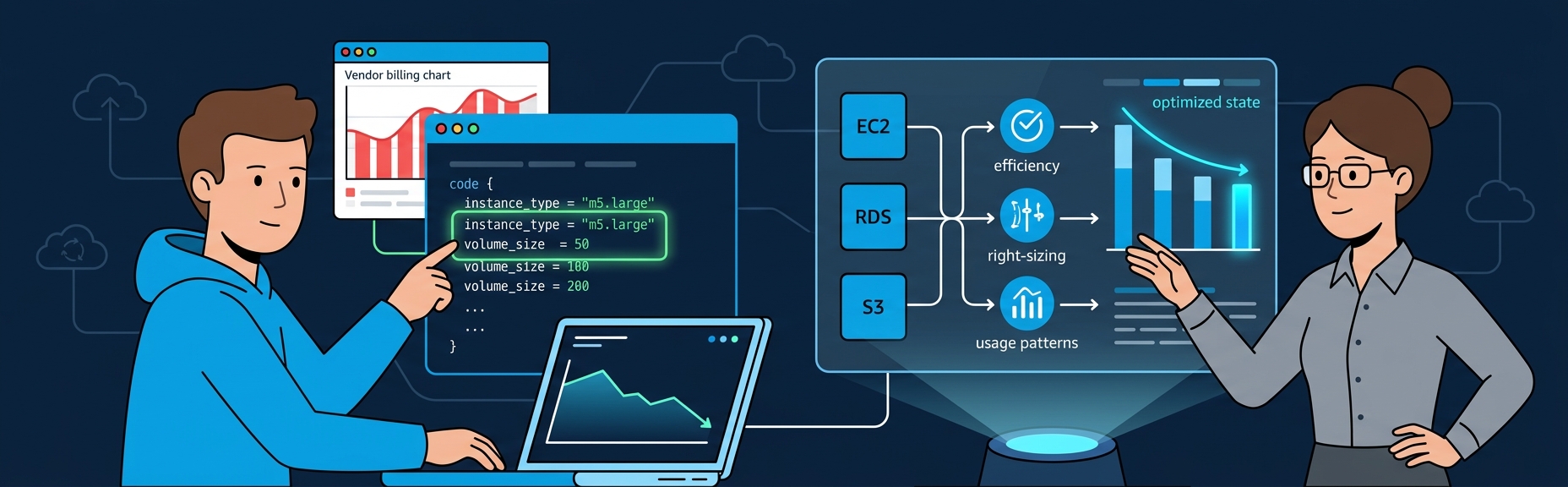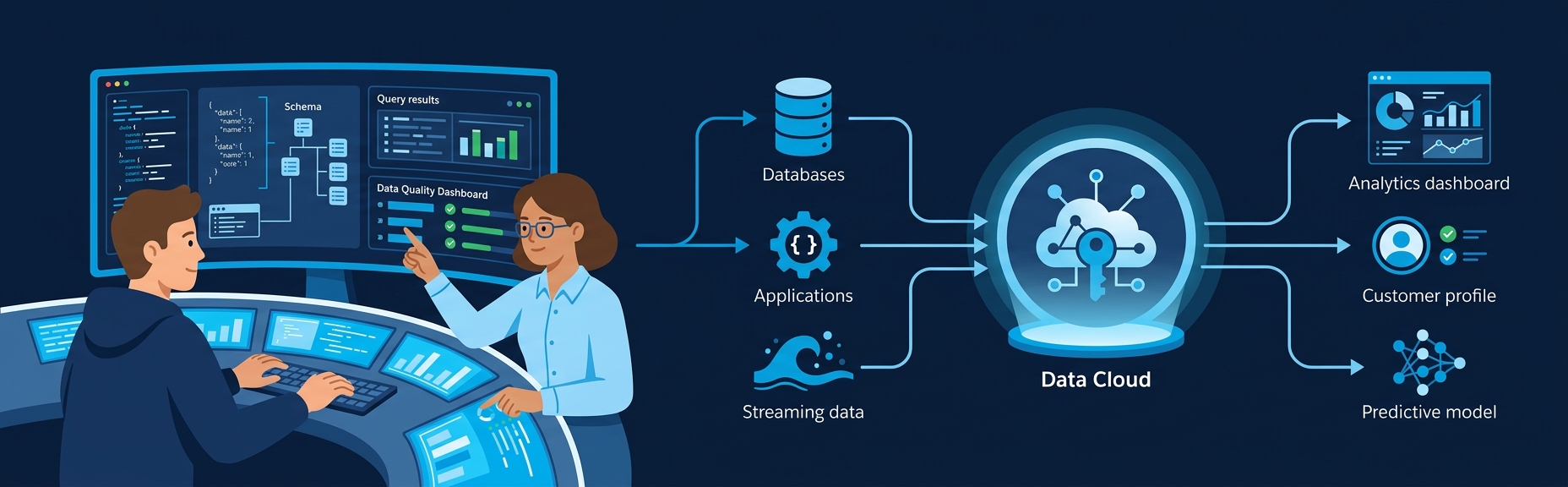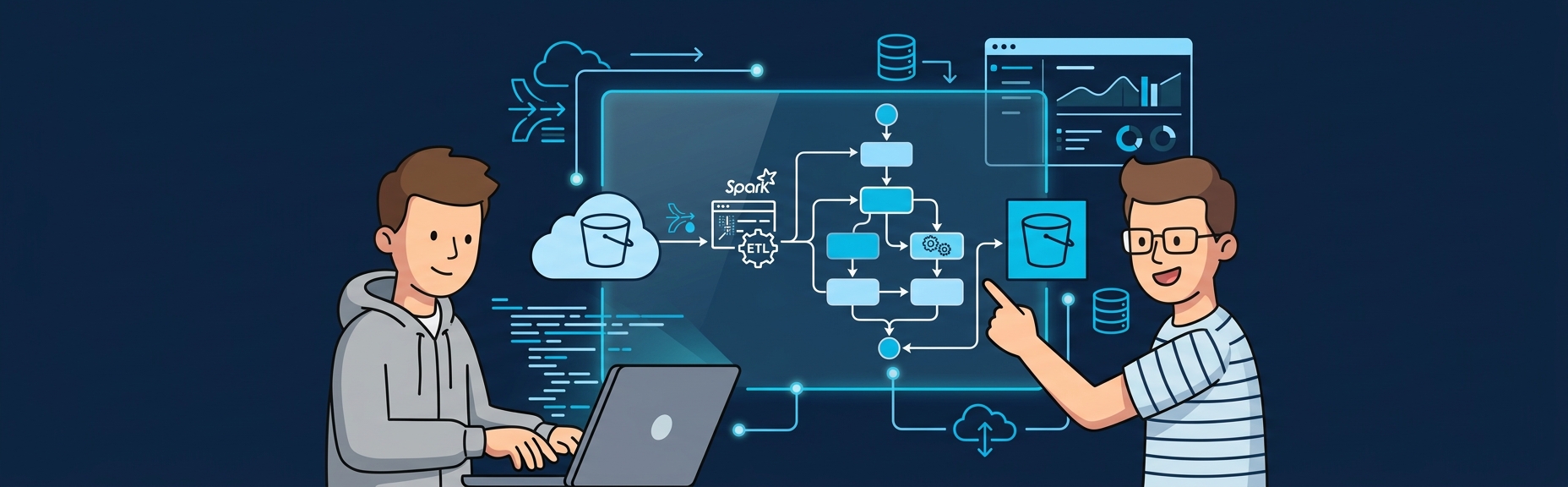
Data pipelines sound simple until you're debugging a Glue job at 3 AM that silently dropped 200,000 records. Here's how I build pipelines on AWS that actually work -- Glue, Step Functions, S3, Athena, and the patterns I keep coming back to.
AWS in Production
Lambda, DynamoDB, S3, CDK, IAM -- real AWS patterns.